Agent Capability Is a System Design Problem: Lessons From a 90% Improvement on CyberGym
TL;DR
- CyberGym is a benchmark that tests whether language-model agents can understand and exploit real-world software vulnerabilities.
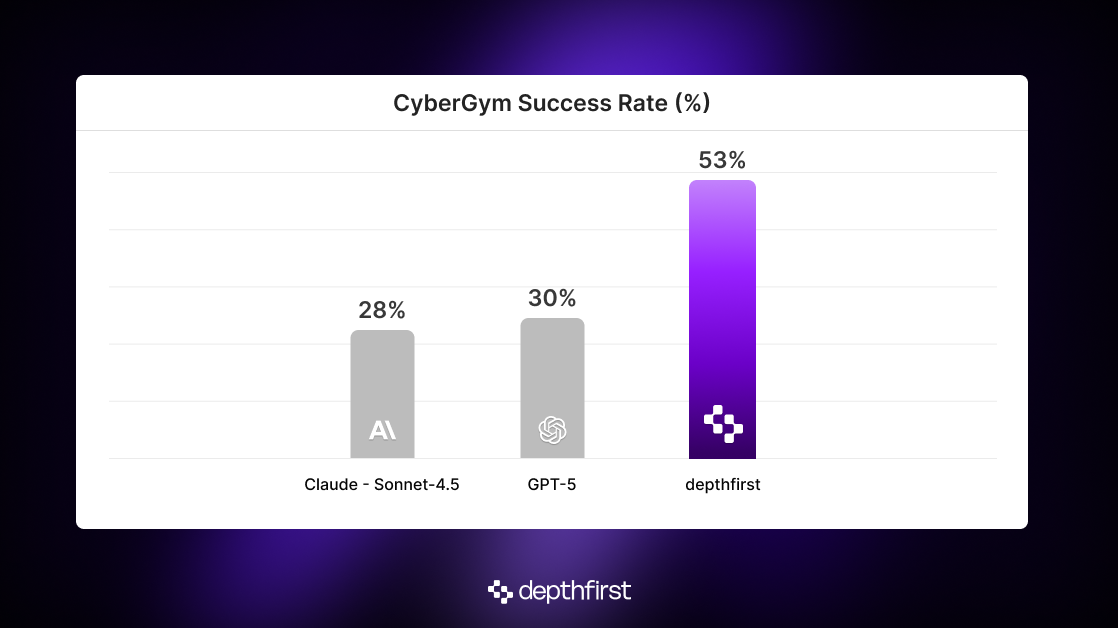
- Prior evaluations suggest current models top out around ~28% success rate.
- By giving the agent the right environment, infrastructure, and architecture, we built an agentic system that reaches ~53% success rate.1
- The broader lesson: model capability is often bottlenecked by system design, and thoughtfully engineered agents can unlock far more capability than naïve prompting reveals.
Update: Anthropic’s Opus-4.5 model, released after our evaluation, reports a 50% CyberGym success rate. This strengthens our broader point: improvements in base-model capability and improvements in agent system design are additive rather than competing. Our system sits on top of the model layer and could incorporate such advances directly.
What is CyberGym?
CyberGym is an evaluation benchmark designed to assess a model’s ability to understand and exploit software vulnerabilities. Its primary task tests whether an agent can reproduce a known vulnerability: given a natural-language description of a bug, the agent must produce a “Proof of Concept” (PoC) input that reliably triggers it. In practice, this means identifying the root cause of the vulnerability in a multi-million-line codebase and crafting an input that makes the program crash in just the right way.
The benchmark addresses several limitations in existing cybersecurity benchmarks, namely in:
- Scale: the dataset contains roughly 1500 real vulnerabilities.
- Utility: the vulnerabilities come from large, production-grade open-source projects, rather than toy programs or artificially injected bugs. They were originally discovered by OSS-Fuzz, Google’s large-scale fuzzing service responsible for thousands of real-world CVEs.
- Feedback: in addition to the source code and vulnerability descriptions, CyberGym includes pre-built instrumented binaries (via ARVO) that accept inputs and return program output. This lets the agent iterate and learn from runtime dynamics, instead of being limited to static analysis alone.
Alongside releasing the benchmark, the CyberGym authors conducted in-depth evaluations of both open and closed-source frontier models (Sonnet-4, GPT-5, Qwen-3). They found that current model performance is poor, with the best system producing successful PoCs only ~20% of the time. Since the benchmark was released, Anthropic has reported a ~28% success rate with Sonnet-4.5. They attribute this increase in performance compared to the original CyberGym paper’s results to “more effective scaffolding", but 28% success rate still suggests that vulnerability reproduction remains far from solved.
Here’s where we disagree.
“Your agent is the average of the five tools it spends the most time with”
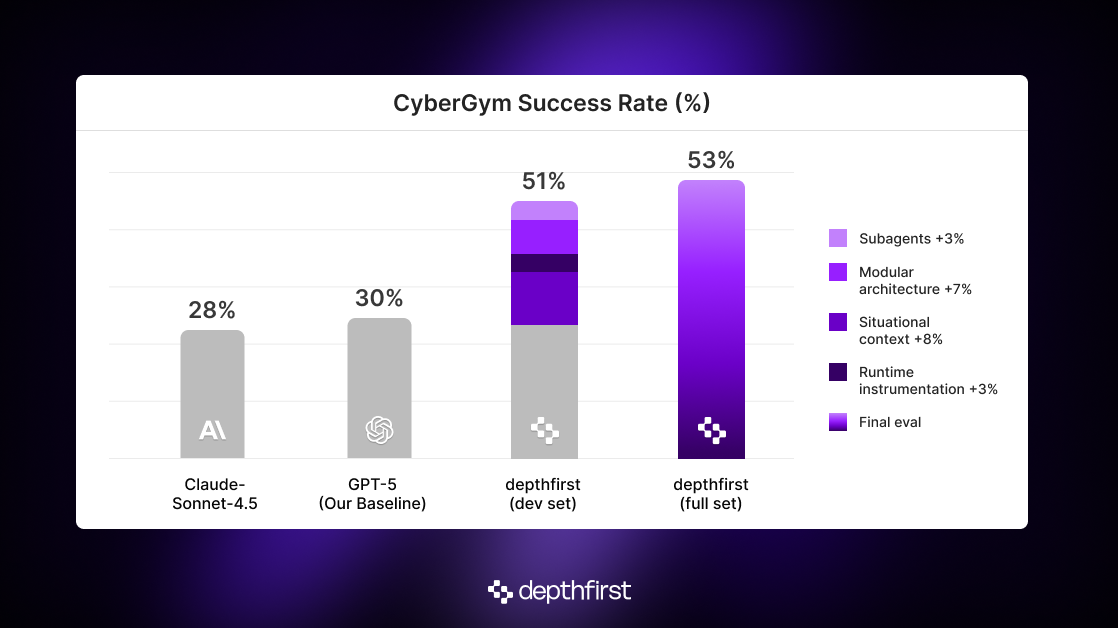
We iterated on a small development set of just 50 examples, and implemented a number of changes that led to the ~90% improvement over SOTA, ranging from base model selection to adapting our multi-agent architecture that we've refined over the last year. Let’s disentangle these changes to understand how much each change contributed to the final result.
The Fundamentals
Model: it’s no secret that different models have different strengths. At depthfirst, we routinely mix and match models depending on the sub-task. For CyberGym, we found that GPT-5 outperformed Claude Sonnet-4.5. Our baseline agent landed at roughly 22% success rate with Sonnet-4.5 and 30% with GPT-5 on our development set. This gap is meaningful, but insufficient to explain the improvements that follow.
Situational context (the overlooked lever):
What matters is not simply telling the agent what to do, but specifying what world it’s operating in. The baseline instructions described the vulnerability and requested a PoC, yet provided no context about the harness that evaluates that PoC. That missing “meta-context” turned out to be the source of an insidious failure mode: agents would produce plausible PoCs, observe that the program didn’t crash, and then conclude that the harness must be wrong. Once the agent adopts this worldview, it stops exploring.
By explicitly stating that PoCs are executed inside a sanitized fuzz harness that will crash given the correct input, we corrected the agent’s internal model of the task. This situational context changed its behavior dramatically: instead of giving up after a failed attempt, the agent kept iterating, testing hypotheses, and refining constraints. It also signaled that reasoning about the harness itself and the constraints it imposes is an essential part of the task.
With these targeted optimizations, our agent’s success rate jumped to almost 38% already.
Infrastructure (cultivating an environment where your agent can thrive)
In the standard CyberGym setup, the agent lives in a tightly constrained environment: it sees only the source code, while its PoC submissions are evaluated on a separate “submission server.” This separation is appealing from an infrastructure standpoint, but it gives the agent no control over the runtime behavior of the program. Without access to runtime behavior, the agent is forced to infer everything from static analysis and the program's final output (crash or no crash).
Intermediate runtime feedback is essential for hypothesis-testing, because it helps the agent pinpoint exactly where the PoC fell short, what data flowed where, and why a crash didn’t occur. This is exactly how humans debug a program by stepping through it and tracing data in real time.
We experimented with a few ways of giving the agent this visibility. Compile-time coverage flags were too noisy. gdb was powerful, but too generic and unwieldy for an LLM to use reliably. The approach that ultimately worked was simpler: letting the agent instrument the program itself. We allowed it to insert targeted “DEBUG” statements to verify assumptions in real time.
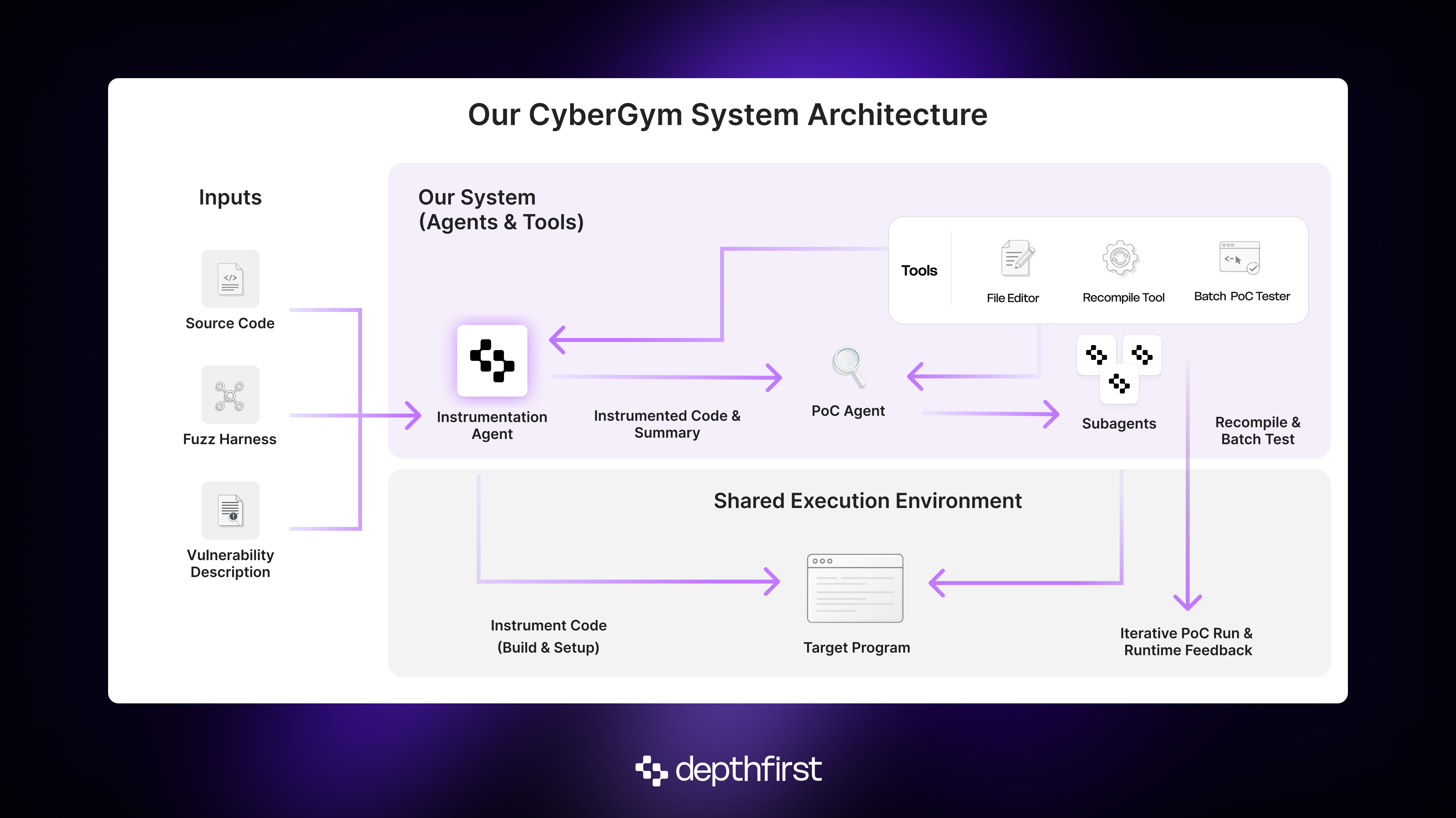
Because we placed the agent in the same image where its PoCs would execute, it could perform the full instrument → build → test cycle autonomously. To support this, we gave it two tools:
- A file editor to make targeted edits to the source code
- A “recompile” tool to update the behavior of the program in response to such edits.3
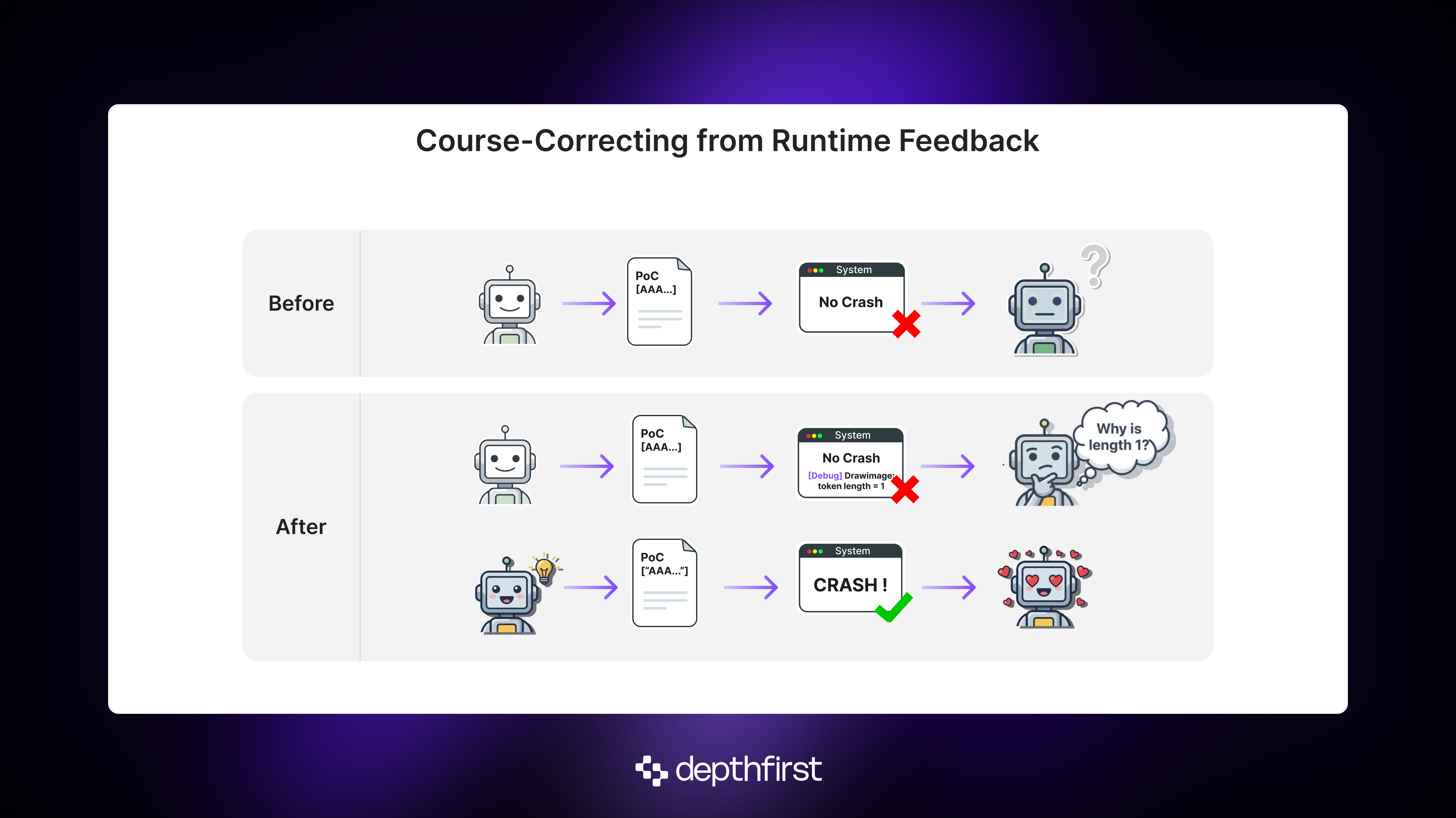
With the ability to control the program directly, performance increased, but only modestly to about 41%. A closer look revealed why: the agent often ignored this new capability, defaulting to static analysis and rapid-fire PoC attempts. There was a clear tension between the long-term planning needed to pull off a successful “instrument → recompile → test” cycle, and the temptation to chase quick wins. Instrumentation worked, but only when the agent bothered to use it. That insight pushed us toward a modular architecture where instrumentation becomes a first-class responsibility.
The agent of your agent is your friend
To actually capitalize on our ability to control the runtime, we introduced a dedicated “instrumentation agent” whose job was to trace data flow from the fuzz harness to the vulnerable method(s). Along the way, it would plant debug statements that might be useful for understanding runtime behavior during PoC execution. The product of this agent was twofold:
- a data-flow summary for the downstream PoC agent, including any input constraints it must obey, and
- a pre-instrumented program that yields rich runtime feedback for every PoC.
We didn’t limit recompilation to the “instrumentation phase”; the agent could still modify program behavior after testing PoCs. We discovered that dedicating a module to this job made the PoC agent much more likely to leverage that capability later on. Only after this modularization was the power of observing runtime behavior was fully realized. At this point, our system achieved a success rate of 48 percent!
We lifted that even further by allowing the PoC agent to spawn near-sighted “subagents” tasked with small, well-defined goals like “instrument this file and recompile” or “investigate the callers of this method”. Crucially, this keeps the main agent’s context window “clean” by shielding it from the details of these exploratory-but-context-intensive subtasks. With that, our success rate climbed to ~51%.
Bells and Whistles
We also added a handful of quality-of-life improvements. While not the primary drivers of performance, we’re certain they’re helpful in keeping the agent from tripping over avoidable friction.
Useful shell tools pre-installed (xxd, hexdump):
Left to its own devices, the agent will try to use these, fail, try to install them, fail, try again with OS-specific instructions, verify the install, and generally waste cycles on infrastructure mishaps. Pre-installing them keeps the agent focused on the task rather than package management.
A “batch” PoC test tool:
“Real hackers” don’t always find the perfect input on the first try. Sometimes you generate a handful of plausible candidates and throw them all at the target. The original single-file submission interface is simple but restrictive. So we allowed the agent to submit a directory with up to 50 PoCs at once for batch testing.
Small conveniences like these remove friction that would otherwise steal the agent’s attention.
What about the remaining ~47%?
Despite all of these improvements, roughly half of the vulnerabilities remain unsolved, and that’s where things get interesting. Some failures come from the agent uncovering different bugs than the ones CyberGym labels as ground truth. Others stem from dataset quality issues: CyberGym is automatically generated, and the harnesses, binaries, and descriptions don’t always line up cleanly.
There’s also a meaningful slice of cases where our system genuinely struggles, in ways that say more about agent design than about CyberGym itself. This deserves a deeper breakdown of its own, and we may explore it separately, but the broader takeaway is clear: there remains significant headroom for agents, and it’s these failures that offer the clearest signals about where to push agent design next.
CyberGym has been a useful proving ground for these ideas, but it is not the goal. The broader lesson is that out-of-the-box systems leave a tremendous amount of capability untapped, and that real gains come from designing the right environment, tools, and structure around the model, before optimizing the model itself (which we are also doing). That principle is central to how we build at depthfirst. Our mission is to secure the world’s software, and we will continue applying these insights across other datasets, customer environments, and open-source ecosystems. There is more work to do, and we are just getting started.
About depthfirst: depthfirst is an applied AI lab pioneering the world’s first general security intelligence platform. We provide an autonomous security system that acts as a full-stack security engineer, automatically detecting, triaging, and remediating vulnerabilities across an organization’s software and systems. Our research team uses a variety of different techniques and models to build cutting-edge intelligence and will continuously share those learnings with the broader community.
1 Because our system is architected specifically for the CyberGym setting, its performance isn’t one-to-one comparable to more generic agent submissions. We see this not as a limitation but as evidence that dedicated system design is the key driver of capability.
2 The full dataset includes two formats: ARVO (≈1370 examples) and OSS-Fuzz archives (≈130 examples). Because the ARVO format provides cleaner, more consistent runtime interfaces, we restricted our evaluation to the ARVO portion. Our 50-example dev set and ~1320-example final test set are drawn from this subset.
3 For final evaluation, every PoC was validated against the original, unmodified test harness to ensure the agent could not cheat by inserting crashes directly.